Ingeniería inversa de la vacuna para el SARS-CoV-2 de BioNTech/Pfizer
Por Bert Hubert | Esta traducción: Víctor R. Ruiz
Traducciones: ελληνικά / عربى / 中文 / 粵文 / bahasa Indonesia / Català / Deutsch / Español / Français / עִברִית / עִברִית2 / Hrvatski / Italiano / Nederlands / 日本語 / 日本語 2 / नेपाली / Polskie / русский / Português / Română / Slovensky / український / Markdown for translating
¡Bienvenidos! En este artículo estudiaremos el código de la vacuna ARNm de BioNTech/Pfizer carácter a carácter.
Quiero darle las gracias al numeroso grupo de personas que se ha tomado su tiempo en revisar la legibilidad y corrección de este artículo. Los fallos restantes responsabilidad mía, así que en caso de encontrar alguno, me gustaría saberlo rápidamente en bert@hubertnet.nl o @PowerDNS_Bert.
Y ahora, puede que estas palabras te resulten chocantes: la vacuna es un líquido que se inyecta en el brazo… ¿cómo puede hablarse de su código fuente?
Es una buena pregunta, así que vamos a comenzar con una pequeña parte del código fuente real de la vacuna BioNTech/Pfizer, también conocida como BNT162b2, Tozinameran o Comirnaty.

La tabla de codones de ARN (Wikipedia).
La vacuna de ARNm BNT162b tiene en su corazón este código digital. Posee una longitud de 4284 caracteres, así que cabe en unos cuantos tuits. Al comienzo del proceso de producción de la vacuna alguien copió este código en la impresora de ADN (sí), que luego convirtió los bytes del disco en moléculas de ADN reales.

Una impresora de ADN Codex DNA BioXp 3200.
Esta máquina produce pequeñas cantidades de ADN, que tras un montón de procesos químicos y biológicos termina como ARN (más sobre esto más tarde) en el vial de la vacuna. Una dosis de 30 migrogramos contiene en realidad 30 microgramos de ARN. Además, hay un sistema inteligente de empaquetado de lípidos (grasiento) que lleva el ARNm a nuestras células.
El ARN es equivalente a la memoria volátil del ADN. El ADN es como el disco de estado sólido de la biología. El ADN es de larga duración, redundante y muy fiable. Pero al igual que los ordenadores no ejecutan código directamente del disco, antes de que ocurra nada, el código se copia a un sistema más rápido y versátil, aunque más frágil.
Para los ordenadores es la RAM y para la biología es el ARN. La similitud es asombrosa. A diferencia del disco sólido, la RAM se degrada rápidamente si no se la alimenta con electricidad. La razón por la que la vacuna de ARNm de Pfizer/BioNTech debe guardarse con los congeladores más congeladores es la misma: el ARNm es una frágil flor.
Cada carácter de ARN pesa del orden de 5.3 · 10-22 gramos, lo que significa que hay 5.7 · 1016 caracteres en una única dosis de 30 microgramos (3.0 · 10-5 gr) de la vacuna. Expresada en bytes, son unos 60 petabytes, aunque debe apuntarse que consiste en unas 14 billones (1.4 · 1013) de repeticiones de los mismos 4285 caracteres. El contenido informativo de la vacuna solo tiene alrededor de un kilobyte. El propio SARS-CoV-2 tiene unos 7.5 kilobytes.
Un poco de información básica
El ADN es un código digital. A diferencia de los ordenadores, que usan 0 y 1, la vida usa A, C, G y U/T (los nucleótidos, nucleósidos o bases).
En los ordenadores, los 0 y 1 se guardan en forma de ausencia o presencia de carga, corriente, como una transición magnética, o como un voltaje, o modulación de señal, o un cambio de reflectividad. En resumen, el 0 y el 1 no son conceptos abstractos, cobran vida bien como electrones u otras encarnaciones físicas.
En la naturaleza, A, C, G y U/T son moléculas, guardadas como cadenas de ADN (o ARN).
En los ordenadores, agrupamos 8 bits en un byte. El byte es la unidad estándar de procesamiento.
La naturaleza agrupa tres nucleótidos en un codón y este es la unidad estándar de procesamiento. Un codón contiene 6 bits de información (2 bits por carácter de ADN, 3 caracteres = 6 bits. Esto son 26 = 64 valores diferentes de codones).
Hasta ahora todo es bastante digital. Si tienes dudas, puedes consultar el documento de la OMS.
Hay más información disponible en «Qué es la vida», que puede ser de ayuda para entender el resto de esta página. O si lo prefieres en vídeo, dispongo de uno de dos horas.
Así que, ¿qué HACE el código?
La idea de una vacuna es enseñar a nuestro sistema inmunitario a luchar contra una patógeno sin enfermar por el camino. Tradicionalmente, se ha hecho inyectando un virus atenuado o incapacitado y un asistente para alarmar al sistema inmunitario y que entre en acción. Esta es una técnica análoga a la que necesitaba millones de huevos (o insectos). También requería un montón de suerte y mucho tiempo. A veces se usaba un virus diferente (no relacionado).
Una vacuna de ARNm consigue el mismo resultado («enseñar a nuestro sistema inmunitario») pero como si fuera un láser: preciso y potente.
Veamos cómo funciona. La inyección contiene un material volátil genético que describe la famosa proteína de la espiga del SARS-CoV-2. A través de ingeniosos procesos químicos, la vacuna es capaz de llevar este material genético hasta alguna de nuestras células.
Obedientemente, éstas comienzan a producir las proteínas de la espiga del SARS-CoV-2 en cantidades suficientemente grandes como para que nuestro sistema inmunitario entre en acción. Enfrentadas a las proteínas de las espigas y, detalle importante, a señales de que las células han sido capturadas, nuestro sistema inmunitario desarrolla una potente respuesta contra diferentes aspectos de la proteína de la espiga Y el proceso de producción.
Y así es cómo se obtiene el 95% de eficacia en la vacuna.
¡El código fuente!
Vayamos ahora al inicio del todo, un buen sitio para empezar. El documento de la OMS tiene esta útil imagen:

Esto es una especie de índice de contenidos. Comenzaremos con «cap», mostrado como un pequeño sombrero.
De la misma forma que no se pueden meter de sopetón un montón de instrucciones en el fichero de un ordenador y esperar que los ejecute sin más, el sistema operativo biológico requiere unas cabeceras, tiene enlazadores y cosas como convenciones de llamadas.
El código de la vacuna comienza con los siguientes dos nucleótidos:
GAEsto es similar a los ejecutables de DOS y Windows que siempre comienzan con los caracteres MZ o los guiones de UNIX que comienzan con #!. Tanto en la vida como en los sistemas operativos, estos dos caracteres no se interpretan literalmente. Pero tienen que estar ahí porque si no, no pasará nada.
El «cap» del ARNm tiene varias funciones. En primer lugar, identifica que el código viene del núcleo. En nuestro caso, por supuesto, no es cierto, nuestro código proviene de una vacunación. Pero no hace falta que se lo digamos a la célula. El cap hace que nuestro código parezca legítimo y lo protege de la destrucción.
Los dos nucleótidos GA iniciales son un poco diferentes químicamente del resto del ARN. En ese sentido, el GA posee una señalización fuera de banda.
La región no traducida 5-prima
Algo de vocabulario técnico. Las moléculas de ARN solo se pueden leer en una dirección. La parte donde comienza la lectura se llama, confusamente, extremo 5’ o «cinco prima». La lectura finaliza en 3’ o el extremo «tres prima».
La vida está compuesta de proteínas (o cosas hechas por proteínas). Y éstas proteínas están descritas en ARN. La conversión del ARN en proteínas se llama traducción.
Aquí tenemos una región no traducida 5’, así que este bit no finaliza la proteína:
GAAΨAAACΨAGΨAΨΨCΨΨCΨGGΨCCCCACAGACΨCAGAGAGAACCCGCCACCAquí encontramos la primera sorpresa. Los caracteres ARN normales son A, C, G y U. En el ADN la U también se conoce como T. Pero aquí encontramos una psi (Ψ), ¿qué está pasando?
Este es uno de los detalles excepcionalmente perspicaces de la vacuna. Nuestro cuerpo tiene un potente sistema antivirus («el original»). Por esta razón, las células son muy reticentes al ARN foráneo e intentan destruirlo denodadamente antes de que hagan nada.
Eso es un problema para la vacuna, ya que necesita burlar el sistema inmunitario. Tras muchos años de experimentación, se descubrió que si se reemplaza la U del ARN por una versión ligeramente modificada de la molécula, nuestro sistema inmunitario pierde el interés. Tal cual.
Así que en la vacuna de BioNTech/Pfizer, cada U ha sido reemplazada por 1-metil-3′-pseudouridina, identificada por Ψ. El detalle realmente ingenioso es que aunque el reemplazo Ψ tranquiliza a nuestro sistema inmunitario, es aceptada por las partes relevantes de la célula como una U normal.
En seguridad informática también conocemos este truco. A veces es posible transmitir una versión ligeramente corrompida de un mensaje, que confunde a los cortafuegos y a los sistemas de seguridad pero que es aceptada por los servidores backend y que luego pueden ser pirateados.
Ahora estamos recogiendo los frutos de la investigación básica realizada en el pasado. Los descubridores de esta técnica Ψ tuvieron que luchar, primero para que financiaran y reconocieran su trabajo. Deberíamos estarles muy agradecidos, y estoy seguro de que los premios Nobel llegarán en su momento.
Muchas personas han preguntado, ¿los virus también pueden usar la técnica Ψ para engañar a nuestros sistemas inmunitarios? La respuesta corta es que parece muy improbable. La vida no tiene la maquinaria necesaria para construir nucleótidos 1-metil-3′-pseudouridina. Los virus necesitan la maquinaria de la vida para conseguir reproducirse y, por lo tanto, esta infraestructura no está disponible. Las vacunas ARNm se degradan rápidamente en el cuerpo humano y no hay posibilidad de que el ARN con las modificaciones Ψ se replique con la Ψ aún ahí. Recomiendo también la lectura de No, las vacunas ARNm no van a afectar a tu ADN.
Bueno, volvamos al extremo 5’. ¿Qué hacen esos 51 caracteres? Como todo en la naturaleza, nada tiene una función clara.
Nuestras células traducen el ARN en proteínas utilizando una máquina llamada ribosoma. El ribosoma es como una impresora 3D de proteínas. Ingiere una cadena de ARN y, basándose en ella, emite una cadena de aminoácidos que luego se pliega como proteína.
Fuente: Usuario Bensaccount de la Wikipedia
{kind=link}
Arriba vemos cómo ocurre eso. La cinta negra inferior es el ARN. La cinta que aparece en el trozo verde es la proteína en formación. Las cosas que vuelan dentro y fuera son aminoácidos y adaptadores para que encajen en el ARN.
Para que funcione, este ribosoma necesita asentarse físicamente en la cadena de ARN. Una vez asentado, puede empezar a formar proteínas basándose en el ARN que ingiere. Te puedes imaginar que no se leen las partes que llegan primero. Esta es solo una de las funciones de la región no traducida: la zona de aterrizaje del ribosoma. La región no traducida proporciona una «introducción».
Además, la región no traducida también contiene metadatos: ¿cuándo debería ocurrir esta traducción? ¿cuánto? Para la vacuna, se seleccionó la región no traducida que más se parecería a «ahora mismo», obtenida del gen globina alfa. Este gen es conocido por crear un montón de proteínas robustamente. En años anteriores, los científicos ya habían encontrado la forma de optimizar aún más esta región no traducida (según el documento de la OMS), así que no es exactamente la región no traducida globlina alfa. Es mejor.
El péptido señal de la glicoproteína S
Como se ha indicado, el objetivo de la vacuna es decirle a la célula que produzca grandes cantidades de la proteína de la espiga del SARS-CoV-2. Hasta ahora, hemos identificado metadatos y «convención de llamadas» en el código fuente de la vacuna. Pero ahora nos vamos a meter en el territorio de las proteínas virales.
Sin embargo, aún tenemos que pasar por una capa de metadatos. Cuando el ribosoma (de la estupenda animación de arriba) ha creado la proteína, esa proteína tiene que ir a algún sitio. Eso está codificado en el «péptido señal de la glicoproteína S (secuencia extendida inicial)».
Una forma de ver ésto es que al comienzo de la proteína hay una especie de etiqueta de dirección, codificada como parte de la propia proteína. En este caso concreto, el péptido señal indica que esta proteína debe salir de la célula a través del retículo endoplasmático. ¡Ni el vocabulario de Star Trek es tan chulo!
El péptido señal no es muy largo, pero cuando revisamos el código hay diferencias entre el ARN viral y la vacuna:
(Aviso que para la comparación he remplazado el Ψ modificado por una U de ARN normal).
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
Virus: AUG UUU GUU UUU CUU GUU UUA UUG CCA CUA GUC UCU AGU CAG UGU GUU
Vacuna: AUG UUC GUG UUC CUG GUG CUG CUG CCU CUG GUG UCC AGC CAG UGU GUU
! ! ! ! ! ! ! ! ! ! ! ! ! ¿Qué pasa aquí? La agrupación del ARN en grupos de tres letras no es casual. Tres caracteres de ARN son un codón. Y cada codón codifica un aminoácido específico. El péptido señal de la vacuna está compuesto por exactamente los mismos aminoácidos que el propio virus.
¿Entonces por qué el ARN es diferente?
Hay 4³=64 codones diferentes, dado que hay 4 caracteres de ARN y cada codón tiene tres de ellos. Pero sólo hay 20 aminoácidos diferentes. Esto significa que hay varios codones que codifican el mismo aminoácido.
La vida usa la siguiente tabla casi universal de correspondencia entre codones de ARN y aminoácidos:
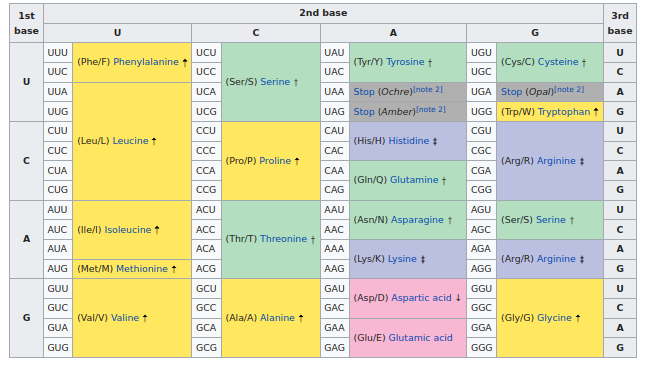
La tabla de codones de ARN (Wikipedia).
En esta tabla podemos ver que las modificaciones en la vacuna (UUU → UUC) son todas sinónimas. El código ARN de la vacuna es diferente, pero produce los mismos aminoácidos y proteínas.
Si miramos con detalle, veremos que la mayoría de los cambios ocurren en la posición del tercer codón, marcados con un «3» arriba. Y si comprobamos la tabla universal de codones veremos que efectivamente esta tercera posición no tiene importancia para el aminoácido resultante.
Entonces, si los cambios son sinónimos, ¿por qué están ahí? Fijándonos atentamente, veremos que todos los cambios excepto uno implican más Cs y Gs.
¿Para qué queremos eso? Como se ha explicado arriba, nuestro sistema inmunitario es muy receloso del ARN exógeno, el código ARN que viene del exterior de la célula. Para evadir la detección, ya se ha remplazado la U del código ARN por Ψ.
Sin embargo, resulta que el ARN con una mayor cantidad de Gs y Cs se convierte más eficientemente en proteínas.
Y la vacuna de ARN consigue eso remplazando muchos caracteres con Gs y Cs, allá donde es posible.
Aún estoy fascinado por el único cambio que no conllevó una C o G adicional, el cambio CCA → CCU. Si alguien conoce la explicación, ¡me encantaría saberlo! Sé que algunos codones son más comunes que otros en el genoma humano, pero también he leído que eso no influye mucho en velocidad de traducción.
La proteína de la espiga
Los siguientes 3777 caracteres de la vacuna ARN también han sido optimizadas para añadir un montón de Cs y Gs. No listaré todo el código para no alargarme demasiado, pero vamos a fijarnos en una secuencia especialmente interesante. Este es el trozo que hace que funcione, la parte que nos ayuda a regresar a la vida normal:
* *
L D K V E A E V Q I D R L I T G
Virus: CUU GAC AAA GUU GAG GCU GAA GUG CAA AUU GAU AGG UUG AUC ACA GGC
Vacuna: CUG GAC CCU CCU GAG GCC GAG GUG CAG AUC GAC AGA CUG AUC ACA GGC
L D P P E A E V Q I D R L I T G
! !!! !! ! ! ! ! ! ! ! Aquí vemos los cambios sinónimos del ARN previsibles. Por ejemplo, en el primer codón vemos que se ha cambiado CUU por CUG. Esto añade otra G a la vacuna, que sabemos que favorece la producción de proteínas. Tanto CUU como CUG codifican el animoácido L o leucina, así que no hay cambios en la proteína.
Cuando comparamos la proteína completa de la espiga en la vacuna, todos los cambios son sinónimos como este… excepto estos dos y es lo que vemos ahí.
El tercer y cuarto codones representan cambios reales. Los aminoácidos K y V han sido remplazados por P, o prolina. Para K, se han necesitado tres cambios («!!!») y para V se han necesitado solo dos («!!»).
Resulta que estos cambios mejoran notablemente la eficiencia vacuna.
Así que, ¿qué está pasando aquí? Si miramos la apariencia real de SARS-CoV-2, veremos que la proteína de la espiga es, bueno, un montón de espigas:
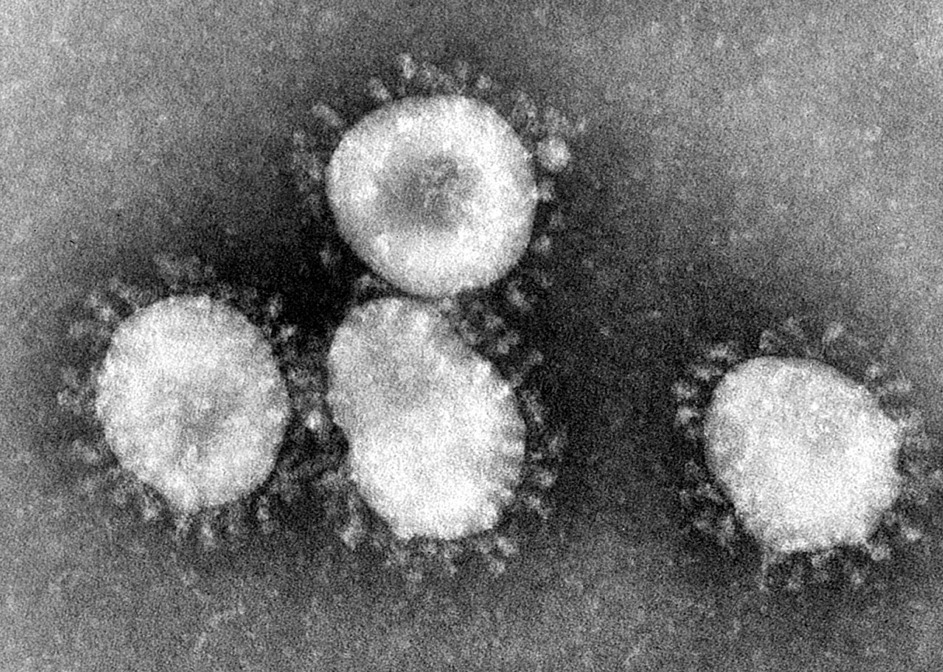
Partículas del virus del SARS (Wikipedia).
Estas espigas están montadas en el cuerpo del virus («la proteína de la nucleocápside»). Pero la verdad es que nuestra vacuna solo genera las propias espigas, no se montan en ningún cuerpo de virus.
Resulta que las proteínas sin modificar y libres colapsan en una estructura diferente. Si se inyectan como vacuna, eso hará que nuestros cuerpos desarrollen inmunidad, sí, pero solo contra la proteína de la espiga colapsada.
Y el SARS-CoV-2 real se muestra como una espiga puntiaguda. La vacuna solo funcionará bien en ese caso.
Entonces, ¿qué hacemos? En 2017, se describió cómo realizar una sustitución doble de prolina en el lugar correcto para hacer que las proteínas S del SARS-CoV-1 y MERS mantuvieran su configuración pre-fusión, incluso cuando no forman parte del virus completo. Esto es posible porque la prolina es una proteína muy rígida. Actúa de férula, estabilizando la proteína en su configuración original para mostrársela al sistema inmunitario.
Las personas que descubrieron esto deberían pasarse el día felicitándose. Deberían emitir ingentes cantidades de satisfacción. Y se las merecerían.
¡Actualización! El laboratorio McLellan contactó conmigo, uno de los grupos que realizó el descubrimiento de las prolinas. Me han dicho que han aplazado la celebración debido a la pandemia, pero que están muy contentos de haber contribuido a las vacunas. También han resaltado la importancia de muchos otros grupos, trabajadores y voluntarios.
El final de la proteína, próximos pasos
Si revisamos el resto del código fuente, encontraremos algunas pequeñas modificaciones al final de la proteína de la espiga:
V L K G V K L H Y T s
Virus: GUG CUC AAA GGA GUC AAA UUA CAU UAC ACA UAA
Vacuna: GUG CUG AAG GGC GUG AAA CUG CAC UAC ACA UGA UGA
V L K G V K L H Y T s s
! ! ! ! ! ! ! ! Al final de la proteína encontramos un codón de parada, indicado por una «s» minúscula. Es una forma cortés de indicar que la proteína debe acabar aquí. El virus original usa el codón de parada UAA, la vacuna usa dos codones de parada UGA, quizás como precaución adicional.
La región no traducida 3’
Al igual que el ribosoma necesitaba un comienzo en el extremo 5’, donde se encuentre la «región no traducida cinco prima», al final de una proteína hay una zona similar llamada la «región no traducida tres prima» o extremo 3’.
Se podría escribir largo y tendido sobre el extremo 3’, pero aquí voy a citar a la Wikipedia: «La región no traducida 3’ juega un papel crucial en la expresión genética influyendo en la localización, estabilidad, exportación y eficiencia de la traducción de un ARN mensajero […] a pesar de nuestro conocimiento actual del extremo 3’, aún esconde varios misterios».
Lo que sabemos es que algunos extremos 3’ tienen mucho éxito promoviendo la expresión proteínica. Según el documento de la OMS, la región tres prima de la vacuna de BioNTech/Pfizer fue seleccionada del «amino-terminal potenciador de la división (AES) del ARNm y el ARN ribosómico 12S codificado mitocondrial para conferir estabilidad al ARN y una alta expresión proteínica». A lo que apostillo, bien hecho.
El AAAAAAAAAAAAAAAAAAAAAA final
El final del ARNm es poliadenilado. Esta es una forma técnica de decir que termina con un montón de AAAAAAAAAAAAAAAAAAA. Parece que incluso el ARNm ya ha tenido suficiente en 2020.
El ARNm puede reutilizarse muchas veces, pero mientras tanto pierde algunas de las As del final. Cuando se acaban las As, el ARNm ya no es funcional y se descarta. De esta manera, la cola poli-A ofrece protección contra la degradación.
Se han realizado estudios para determinar el número óptimo de A al final de las vacunas de ARNm. Según leo en la literatura abierta disponible, sería alrededor de 120.
La vacuna BNT162b2 termina con:
****** ****
UAGCAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAGCAUAU GACUAAAAAA AAAAAAAAAA
AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAAAAAAA AAAAEsto son 30 As y luego un «un enlazador de 10 nucleótidos» (GCAUAUGACU) seguido de otras 70 As.
Hay varias teorías de por qué el enlazador está ahí. Algunas personas me han sugerido que está relacionado con la estabilidad del ADN plasmídico, y también he recibido ésto de un verdadero experto:
«El enlazador de 10 nucleótidos en la cola de poli-A facilita unir los fragmentos del ADN sintético que se convierte en plantilla para transcribir el ARNm. También reduce el emparejamiento incorrecto de la polimerasa ARN T7 por lo que el ARNm transcrito es más uniforme en longitud».
En resumen
Con todo esto, ahora conocemos los contenidos exactos del ARNm de la vacuna BNT162b2 y por qué están ahí la mayoría de sus componentes:
- El CAP para asegurarse de que el ARN parece ARNm normal.
- Una región no traducida 5’ bien conocida y optimizada.
- Un codón optimizado de péptido señal para enviar la proteína de la espiga a su destino apropiado (copia exacta del virus original).
- Una versión optimizada del codón de la espiga original, con dos sustituciones prolina para asegurar que la proteína conserva la forma adecuada.
- Una región no traducida 3’ optimizada y exitosa.
- Una cola poli-A un tanto misteriosa con un enigmático enlazador.
Las optimizaciones de codones añaden un montón de Gs y Cs al ARNm. Además, el uso de Ψ (1-metil-3’-pseudouridina) en lugar de U ayuda a evadir el sistema inmunitario, por lo que el ARNm sobrevive lo suficiente como para entrenarlo.
Más información
En 2017 hice dos presentaciones sobre el ADN, que se pueden ver aquí. Como esta página, está destinada a personas con conocimientos de informática.
Además, desde 2001 mantengo una paǵina sobre ADN para programadores.
También podría ser de interés esta introducción a nuestro increíble sistema inmunitario.
Finalmente, esta lista de mis artículos del blog tienen bastantes contenidos relacionados con el ADN, SARS-CoV-2 y COVID.